Internet w bibliotekach II - łączność, współpraca, digitalizacja, Wrocław, 23-26 września 2003 roku

Internet w bibliotekach II - łączność, współpraca, digitalizacja, Wrocław, 23-26 września 2003 roku |
|
![]()
- Spis treści
- Poprzedni - Następny ![]()
1. WprowadzenieNa przestrzeni ostatnich 10-13 lat daje się w Polsce zaobserwować dynamiczny proces komputeryzacji katalogów bibliotecznych.. W tym czasie powstało wiele krajowych systemów bibliotecznych, a ponadto biblioteki lub grupy bibliotek zakupiły pięć bibliotecznych systemów zagranicznych. Proces ten przebiegał równolegle do mniej lub bardziej dynamicznie postępującego, częściowo koordynowanego przez Komitet Badań Naukowych (obecnie Ministerstwo Nauki i Informatyzacji) rozwoju łączności sieciowej i w konsekwencji, wraz z rozwojem technologii, pojawiania się coraz większych ułatwień w dostępie do Internetu. Istniały zatem, niemal od początku, warunki to tego, żeby w projektowaniu procesów komputeryzacji katalogów uwzględnić dostępne standardy i narzędzia oraz wykorzystać różnorodne możliwości komunikacji. Niestety, proces komputeryzacji katalogów bibliotecznych w Polsce nigdy nie był nadrzędnie koordynowany. Pojawiające się sporadyczne inicjatywy współpracy miały zwykle charakter spontaniczny, były oddolną inicjatywą i nie wynikały z istnienia centralnej koncepcji komputeryzacji katalogów bibliotecznych. Ograniczanie pola zainteresowania wyłącznie do katalogu własnej biblioteki było dość powszechną praktyką. W efekcie wytworzono wiele danych, często niezgodnych z formatem USMARC, zawierających nieujednolicone hasła. Pierwsza inicjatywa zastosowania łączności sieciowej do współkatalogowania podjęta została przez grupę 4 bibliotek [1], które w 1992 r. zakupiły oprogramowanie biblioteczne firmy VTLS Inc. oraz zdecydowały się na zastosowanie formatu USMARC (obecnie MARC 21). Biblioteki te zapoczątkowały w 1993 roku współpracę w zakresie budowania kartoteki haseł wzorcowych. Decyzja ta wymagała dodatkowo opracowania materiałów metodycznych dotyczących kartotek haseł wzorcowych i formatów MARC oraz upowszechnienia w środowisku bibliotekarzy tych pojęć oraz ich znaczenia dla katalogów komputerowych, bowiem problemy te były w bibliotekach praktycznie nieznane. Od sierpnia 1993 roku do bazy ulokowanej na serwerze Biblioteki Uniwersyteckiej w Warszawie zaczęto wprowadzać rekordy dla nazw osobowych, ciał zbiorowych, tytułów ujednoliconych i tytułów serii oraz słownictwa języka KABA. Opiekę nad wspólnie budowaną i wspólnie wykorzystywaną bazą KHW sprawowała Biblioteka Uniwersytecka w Warszawie. W początkowym okresie (ok. 9 miesięcy), gdy serwer BUW nie był jeszcze podłączony do sieci, współpraca ta realizowana była poprzez przesyłanie na taśmach danych utworzonych w poszczególnych bibliotekach. Ten początkowy okres dostarczył współpracującym bibliotekom bardzo wiele negatywnych doświadczeń wynikających z konieczności pracy w trybie offline. Z inicjatywy wspólnej kartoteki haseł wzorcowych wyrosła Centralna Kartoteka Haseł Wzorcowych (CKHW), od 1996 roku prowadzona przez, formalnie do tego celu powołaną w Bibliotece Uniwersyteckiej jednostkę - Centrum Formatów i Kartotek Haseł Wzorcowych. Jest ona obecnie istotnym elementem katalogu centralnego NUKAT. Po 10 latach współkatalogowania CKHW liczy ponad 868 tys.[2] rekordów haseł wzorcowych i budowana jest przez 34 biblioteki stosujące różne systemy biblioteczne, a wykorzystywana, także niejawnie, przez liczną rzeszę bibliotek, które chcą i potrafią z jej zasobów skorzystać. Zatem obchodzimy w tym roku dziesiątą rocznicę zastosowania Internetu do współkatalogowania zbiorów w Polsce. Niestety, wiele bibliotek nie widziało przez te lata sensu uczestniczenia we współtworzeniu oraz wykorzystywania zasobów CKHW. Pomimo posiadania systemów z kontrolą haseł wzorcowych pozostawiło ten problem do automatycznej obsługi przez stosowane oprogramowanie, ze wszystkimi negatywnymi konsekwencjami takiego postępowania. Kolejnym ważnym krokiem w wykorzystaniu Internetu do katalogowania zbiorów w kraju było utworzenie w 1995 roku, budowanego metodą współkatalogowania centralnego katalogu czasopism (CKTCz). Inicjatywa ta znowu została zaproponowana i zrealizowana przez biblioteki stosujące system VTLS, a katalog ulokowano na serwerze Biblioteki Uniwersytetu Gdańskiego, która przez siedem lat zajmowała się także jego prowadzeniem. 2. Utworzenie katalogu centralnego NUKAT- nowa organizacja katalogowania zbiorówW 1998 roku zapoczątkowano w Polsce prace projektowe nad koncepcją katalogu centralnego. Prowadził je wyłoniony wówczas z przedstawicieli zainteresowanych grup bibliotek[3] Zespół Koordynacyjny. Zespół ten w ciągu pół roku opracował koncepcję Katalogu Centralnego, opierając ją na wykorzystaniu Internetu zarówno do budowania katalogu, jak też do realizowania jego funkcji informacyjnej. Katalog centralny NUKAT uruchomiony został w połowie 2002 r. Z czterech lat, które upłynęły do tego momentu, ponad dwa lata zabrały spory na temat projektu katalogu. Zasadniczo koncepcja katalogu centralnego jako budowanego metodą współkatalogowania źródła gotowych rekordów nie była kwestionowana, ale nie zgodzono się jednak na procedury budowania bazy i proponowaną organizację współpracy. Realizacja projektu rozpoczęła się wiosną 2001 roku po dokonaniu wyboru oprogramowania do obsługi katalogu centralnego i po podpisaniu kontraktu z firmą VTLS na zakup systemu Virtua. Przystąpiono wówczas do współpracy z producentem nad dostosowaniem oprogramowania do obsługi zaprojektowanej w koncepcji katalogu organizacji współpracy w zakresie współkatalogowania. Dopiero w tym samym roku zaistniały warunki do powołania do życia zespołu Centrum NUKAT, którego zadaniem było prowadzenie katalogu centralnego. 5 lipca 2002 roku wprowadzony został do katalogu centralnego pierwszy rekord bibliograficzny. W momencie startu w przedsięwzięciu brało udział 27 bibliotek, wcześniej uczestniczących w budowaniu CKHW i przeszkolonych do współpracy z katalogiem Centralnym NUKAT. Centralna Kartoteka Haseł Wzorcowych, licząca w dniu uruchomienia bazy katalogu centralnego NUKAT ponad 720 tys., rekordów została w całości przeniesiona do katalogu centralnego, zaś Centralny Katalog Czasopism włączono do katalogu centralnego we wrześniu 2002 roku, wnosząc 21 943 rekordy bibliograficzne dla wydawnictw ciągłych, wraz z informacją o miejscu przechowywania poszczególnych tytułów. Budowanie bazy rekordów bibliograficznych dla książek i stopniowo kolejnych typów dokumentów rozpoczęto w katalogu centralnym od zera. Obecnie tworzy się w katalogu centralnym, obok rekordów bibliograficznych dla książek, rekordy dla druków muzycznych, dokumentów dźwiękowych, dokumentów elektronicznych. Docelowo w katalogu centralnym znajdą się w jednej bazie wszystkie typy dokumentów przechowywanych w polskich bibliotekach naukowych. Jak już wcześniej wspomniano, katalog centralny NUKAT obsługiwany jest przez system biblioteczny Virtua firmy VTLS z Blacksburga w Stanach Zjednoczonych. Z katalogiem centralnym współpracują 24 biblioteki użytkujące oprogramowanie Virtua, tożsame z oprogramowaniem katalogu centralnego, 5 bibliotek użytkujących oprogramowanie Horizon, 4 użytkujące oprogramowanie ALEPH i 1 Prolib. Do współkatalogowania przygotowuje się Biblioteka Narodowa stosująca system Innopac i między innymi Biblioteka Politechniki Świętokrzyskiej, pierwsza użytkująca system Q Series. Wprowadzanie danych do katalogu centralnego oraz kopiowanie ich do katalogu lokalnego odbywa się za pomocą oprogramowania typu klient systemu Virtua, który jest nieodpłatnie udostępniany bibliotekom współpracującym w ilości gwarantującej lokalnie płynność katalogowania. W momencie kopiowania do rekordu bibliograficznego w katalogu centralnym dopisywany jest kod lokalizacji dokumentu. Kod ten zapewnia też łączność z danym katalogiem lokalnym. Wyszukiwanie w katalogu centralnym NUKAT odbywa się za pomocą oprogramowania Chameleon iPortal i jest możliwe za pośrednictwem Internetu. Dane w katalogu centralnym NUKAT budowane są zgodnie z obowiązującymi w Polsce przepisami katalogowania (dostosowanymi do zaleceń międzynarodowych), regulującymi zasady tworzenia opisu bibliograficznego, zasady doboru i formułowania haseł oraz zasady dotyczące budowy katalogu, a więc zawierają rekordy bibliograficzne tworzone według ujednoliconych zasad, kontrolowane centralną kartoteką haseł wzorcowych. Dane w katalogu centralnym zapisywane są w formacie MARC 21 i przekazywane do innych systemów w formacie wymiennym. Zapewnia to spójność danych, jednoznaczną identyfikację dokumentów, efektywne wyszukiwanie w bazie centralnej i bazach lokalnych (także z wykorzystaniem protokołu Z39.50), umożliwia wymianę danych w skali kraju oraz wymianę międzynarodową. Katalog centralny NUKAT, dzięki zastosowaniu oprogramowania bibliotecznego Virtua, przystosowany jest do obsługi kilku języków charakterystyki przedmiotowej. Ta cecha systemu znajdzie zastosowanie, gdy współkatalogowanie rozpocznie Biblioteka Narodowa, stosująca własny język haseł przedmiotowych oraz biblioteki medyczne stosujące specjalistyczny język charakterystyki przedmiotowej - Medical Subject Headings (MeSH). Wyszukiwanie w katalogu centralnym możliwe będzie z wykorzystaniem indeksu przedmiotowego jednego wybranego języka lub we wspólnym indeksie przedmiotowym obejmującym wszystkie trzy języki. Użytkownik jednak zawsze otrzyma informację, z którego języka pochodzi znajdujący się w indeksie termin lub hasło przedmiotowe rozwinięte. Obecnie w katalogu centralnym do charakterystyki przedmiotowej dokumentów stosowany jest język haseł przedmiotowych KABA, zgodny pod względem metody tworzenia i gramatyki z najbardziej rozpowszechnionym na świecie językiem haseł przedmiotowych Biblioteki Kongresu (LCSH) oraz jego francuskim odpowiednikiem RAMEAU. W rekordach dla każdego terminu słownictwa języka KABA znajduje się jego angielski i francuski odpowiednik z języka LCSH i RAMEAU. Do katalogu centralnego wprowadzane są także rekordy haseł przedmiotowych rozwiniętych, gotowe do użycia w rekordach bibliograficznych. Słownictwo tego języka jest współtworzone i wykorzystywane głównie przez polskie biblioteki naukowe. Jego stosowanie nie jest jednak obowiązujące w katalogu centralnym i nie warunkuje uczestniczenia we współkatalogowaniu. Do katalogu centralnego przyjmowane są rekordy bibliograficzne bez charakterystyki przedmiotowej, która może być wprowadzona w trybie modyfikacji rekordu bibliograficznego przez inną bibliotekę w terminie późniejszym. Modyfikacja taka wprowadzana jest następnie automatycznie do katalogów bibliotek stosujących język haseł przedmiotowych KABA. Do katalogów nie stosujących języka haseł przedmiotowych KABA modyfikacja taka nie wchodzi. W podobnym trybie będzie realizowane zaopatrywanie rekordów bibliograficznych w charakterystyki przedmiotowe w JHPBN po przystąpieniu do współkatalogowania przez Bibliotekę Narodową. Katalog centralny NUKAT działa już rok. Mechanizm współkatalogowania uruchomiony w lipcu 2002 roku, pracuje sprawnie i rozwija się zgodnie z oczekiwaniami. Obecnie we współkatalogowaniu uczestniczą 34 biblioteki, o 7 więcej niż w chwili uruchomienia katalogu, 3 dalsze przygotowują się do współpracy. Miesięcznie wpływają do bazy NUKAT średnio 10 532 rekordy bibliograficzne dla dokumentów zwartych, 369 rekordów dla czasopism i średnio 12 207 rekordów kartoteki haseł wzorcowych. Wszystkie prawidłowe rekordy wprowadzone do bufora bazy NUKAT po dwóch dniach są dostępne do skopiowania. Baza rekordów bibliograficznych, budowana drogą współkatalogowani, od zera, liczy obecnie 134 524[4], a w katalogach lokalnych, dzięki skopiowaniu gotowych rekordów powstało łącznie ponad 243 137 rekordów[5]. Każdy z wprowadzonych do katalogu centralnego rekordów bibliograficznych dla wydawnictw zwartych został wykorzystany w katalogach lokalnych średnio 1,92 raza. Największym zainteresowaniem cieszą się rekordy dla dokumentów wydanych w latach 2001-2003, czyli najnowsze. Niektóre skopiowane zostały kilkanaście razy. Dokumenty sprzed 2001 roku są rzadziej kopiowane, ponieważ rekordy dla nich przeważnie znajdują się już w katalogach lokalnych lub akurat nie są przedmiotem katalogowania w innych bibliotekach. Należy jednak oczekiwać, że z czasem i te rekordy zostaną wykorzystane, gdy biblioteki przystąpią do retrokonwersji swoich katalogów lub do systematycznej wymiany istniejących w katalogach lokalnych rekordów na rekordy pochodzące z katalogu centralnego. Zyskają dzięki temu dopisanie do rekordu w katalogu centralnym kodu lokalizacji własnej biblioteki, zaś czytelnik zyska pełniejszą informacje o miejscu przechowywania tych dokumentów.
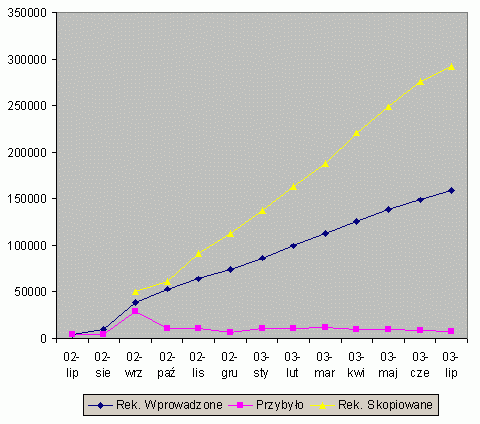
Rysunek 1: Przyrost rekordów bibliograficznych dla dokumentów zwartych i ciągłych w katalogu centralnym NUKAT i w katalogach lokalnych.[6] Biblioteki, które uczestniczą we współkatalogowaniu, zyskują nie tylko możliwość nielimitowanego wykorzystania gotowych rekordów w swoim katalogu, ale także zastosowania w nich opisów przedmiotowych wytworzonych w innych bibliotekach. Oszczędzają więc zarówno na opracowaniu formalnym, jak i na opracowaniu przedmiotowym. Wszelkie korekty i modyfikacje wprowadzane w katalogu centralnym pojawiają się automatycznie w katalogach lokalnych, ponieważ wszystkie rekordy zastosowane w katalogach lokalnych, pochodzące z katalogu centralnego, dzięki identyfikacji poprzez numer kontrolny rekordu są automatycznie aktualizowane. Po roku współkatalogowania zawartość katalogu centralnego przedstawia się następująco: Rekordy bibliograficzne w katalogu NUKAT dla wydawnictw zwartych.[7]
Rekordy bibliograficzne w katalogu NUKAT dla wydawnictw ciągłych.[8]
3. Możliwości wykorzystania danych z katalogu centralnego przez biblioteki nie współpracujące z katalogiem NUKAT.Biblioteki, które nie uczestniczą we współkatalogowaniu również mogą budować swoje katalogi lokalne poprzez kopiowanie gotowych rekordów. Gotowe rekordy udostępniane są nieodpłatnie wszystkim bibliotekom, które są nimi zainteresowane, jednakże Centrum NUKAT nie dostarcza w takim przypadku narzędzi do ich pobierania. Takie narzędzia zainteresowana biblioteka musi nabyć lub opracować we własnym zakresie. Pewną inicjatywę w tej sprawie podejmują producenci najbardziej rozpowszechnionych w Polsce krajowych systemów bibliotecznych, a Centrum NUKAT oferuje pomoc w opracowywaniu tych narzędzi, udostępniając bazę testową, informacje, konsultacje, stosując różnego rodzaju dodatkowych rozwiązań. Jeśli biblioteka zgłosi w Centrum NUKAT fakt pobierania rekordów[9] z katalogu centralnego, jej katalog lokalny może być objęty systemem automatycznej aktualizacji danych. Praktyka dołączania kodu lokalizacji do skopiowanych rekordów dotyczy jednak tylko bibliotek naukowych, publicznych wojewódzkich oraz, niemieszczących się w tych dwóch grupach bibliotek posiadających szczególnie cenne, unikatowe kolekcje. Biblioteka, która decyduje się budować swój katalog lokalny poprzez kopiowanie gotowych rekordów z katalogu centralnego, bez względu na to, czy uczestniczy we współkatalogowaniu w katalogu centralnym czy też jest tylko jego biernym użytkownikiem, powinna dążyć do tego, aby katalog centralny był jedynym źródłem rekordów dla katalogu lokalnego. Kopiowanie rekordów z wielu źródeł - bezpośrednio z innej biblioteki lub np. poprzez katalog KaRo - jest działaniem krótkowzrocznym przynoszącym wprawdzie doraźne korzyści w postaci przyspieszenia budowy katalogu lokalnego, ale niesie niebezpieczeństwo utraty spójności danych i może to mieć pewne negatywne konsekwencje, np. zagranie niewłaściwego rekordu, ale o przypadkowo identycznym numerze kontrolnym. Budowanie katalogu lokalnego poprzez kopiowanie z różnych źródeł wymusza także konieczność ręcznej obsługi rekordów spoza puli skopiowanej z katalogu centralnego w wyniku nieobjęcia ich systemem automatycznej modyfikacji. Może się też okazać szczególnie dolegliwe, gdy biblioteka chce podjąć jakieś globalne działania z wykorzystaniem danych z katalogu centralnego, np. jednorazowe uzupełnienie w rekordach bibliograficznych charakterystyki przedmiotowej na podstawie danych z katalogu centralnego. W przypadku niespójnych danych zabieg taki możliwy do automatycznego przeprowadzenia będzie dotyczył tylko danych skopiowanych z katalogu centralnego. Także istotną konsekwencją czerpania danych z kilku źródeł powoduje, że informacja o zbiorach danej biblioteki zawarta w katalogu centralnym w kodach lokalizacji staje się niepełna. 4. Uwagi końcoweUruchomienie Narodowego Uniwersalnego Katalogu Centralnego NUKAT, jako budowanego metodą współkatalogowania źródła gotowych rekordów, należy uznać za ogromny sukces środowiska bibliotekarskiego w Polsce. Pierwsze korzyści już są widoczne. Wiele bibliotek, dzięki oszczędnościom czasowym poczynionym na katalogowaniu wpływu bieżącego, mogło zająć się komputerowym katalogowaniem zbiorów dawniejszych, opisanych wyłącznie w katalogach kartkowych. Nastąpiło więc, dzięki likwidacji dublowania pracy, przyspieszenie katalogowania i obniżenie jego kosztów - przynajmniej w bibliotekach, które uczestniczą w przedsięwzięciu. Stopniowo poprawia się jakość danych w katalogach lokalnych. Ma to wpływ na efektywność wyszukiwania także przy wykorzystaniu innych niż katalog centralny narzędzi, np. KaRo. Nigdy jeszcze, żadna inicjatywa nie spowodowała takiej zmiany jakościowej w organizacji pracy bibliotek. Zainteresowanie nowych użytkowników, zarówno współkatalogowaniem, jak i tylko wykorzystaniem gotowych danych jest bardzo duże. Również czytelnicy otrzymali po raz pierwszy w jednym miejscu pełną informację o tym, co wpłynęło, co zostało skatalogowane w ostatnim okresie w polskich bibliotekach i gdzie jest przechowywane. Informacja ta ciągle jeszcze nie jest z punktu widzenia czytelników satysfakcjonująca, ale np. już w przypadku nowości prawie stuprocentowa, a poprawi się jeszcze po przystąpieniu do współkatalogowania Biblioteki Narodowej. Sytuacja ta będzie się zmieniać w miarę napełniania bazy oraz w miarę przystępowania do współpracy nowych bibliotek. Obecnie żywo dyskutowany jest problem scalenia w katalogu centralnym danych z katalogów lokalnych wcześniej utworzonych (sprzed 2002). W projekcie zapowiadany był taki proces. Miał dotyczyć wyłącznie katalogów lokalnych wytworzonych z wykorzystaniem rekordów KHW pochodzących z CKHW. Jednakże uzyskanie w katalogu centralnym zbioru scalonych rekordów, połączone ze zlikwidowaniem rekordów zdublowanych i zachowaniem kodów lokalizacji, a następnie zastąpienie odpowiedników tych rekordów w katalogach lokalnych rekordami pochodzącymi z katalogu centralnego, jest praktycznie niemożliwe. Wymagałoby ogromnej pracy ręcznej, co wiąże się z kosztami i zawsze niesie ryzyko uszkodzenia danych w katalogach lokalnych oraz pojawienia się katalogu centralnym zdublowanych rekordów dla tego samego dokumentu. Konsekwencją tego mogą być daleko idące. Najłagodniejszą z nich wydaje się niepełna informacja o miejscu przechowywania dokumentu, gdy każdy ze zdublowanych rekordów zostanie skopiowany do innych bibliotek. Najgroźniejszą jest możliwość uszkodzenia danych w katalogach lokalnych poprzez zagranie niewłaściwych rekordów przez rekordy pochodzące z katalogu centralnego. Sprawa ciągle jest otwarta, ale Centrum NUKAT skłania się do zrezygnowania z tej operacji, na rzecz stopniowej wymiany danych w katalogach lokalnych bibliotek na dane pochodzące z katalogu centralnego. Centrum deklaruje gotowość opracowywania i udostępniana narzędzi ułatwiających ten proces. Przypisy[1] Współpracę zainicjowały Biblioteka Jagiellońska, Biblioteka Uniwersytetu Gdańskiego, Biblioteka Akademii Górniczo Hutniczej oraz Biblioteka Uniwersytecka w Warszawie, która udostępniła miejsce na serwerze oraz podjęła się prowadzenia kartoteki. [2] Dane na podstawie statystyki z 7.07.2003 roku. [3] Inicjatywę opracowania projektu podjęli przedstawiciele grupy bibliotek VTLS skupieni wokół Porozumienia o Współpracy Polskich Bibliotek Użytkujących i Wdrażających System VTLS, przedstawiciele grupy bibliotek Horizon skupieni w porozumieniu "Biblioteka z Horyzontem" oraz Biblioteka Narodowa. [4] Dane z 7.07.2003 roku. [5] Dane dotyczą tylko rekordów dla wydawnictw zwartych. Rekordy bibliograficzne dla wydawnictw ciągłych skopiowane zostały do katalogów lokalnych średnio 2,4 raza, dając łącznie prawie 59 000 rekordów bibliograficznych w katalogach lokalnych. Współczynnik wykorzystania rekordów KHW jest niemożliwy do obliczenia, ponieważ rekord hasła raz skopiowany do katalogu lokalnego, znajduje wielokrotne zastosowanie w rekordach bibliograficznych. [6] Wykres według danych z 31.07.2003 roku. [7] Dane wg statystyki z 25.07.2003 roku. [8] Dane wg statystyki z 30.07.2003 roku. [9] W niektórych systemach możliwe jest niejawne kopiowanie rekordów bibliograficznych z katalogu centralnego lub kopiowanie z wykorzystaniem katalogu KaRo. |
![]()
- Spis treści
- Poprzedni - Następny ![]()
(C) 2003 EBIB
Praktyczne wykorzystanie Internetu do racjonalnego katalogowania zbiorów w polskich bibliotekach naukowych / Maria Burchard // W:Internet w bibliotekach II [Dokument elektroniczny] : łączność, współpraca, digitalizacja : Wrocław, 23-26 września 2003 roku. - Dane tekstowe. - [Warszawa] : Stowarzyszenie Bibliotekarzy Polskich, K[omisja] W[ydawnictw] E[lektronicznych], Redakcja "Elektronicznej Biblioteki", 2003. - (EBIB Materiały konferencyjne). - Tryb dostępu : http://www.ebib.pl/publikacje/matkonf/iwb2/burchard.php . - Internet w bibliotekach II. - ISBN 83-915689-5-4